Introduction
Real-time editing is harder than offline generation. Average throughput is not enough—the system has to respond with low latency and stable outputs often enough for a human to stay in the loop.
This project pushes a FLUX2-based image editor toward that regime along three fronts: inference acceleration to make serving fast, architectural changes to reshape the model for causal editing, and reinforcement-learning-based distillation to compress the step budget without giving up quality.
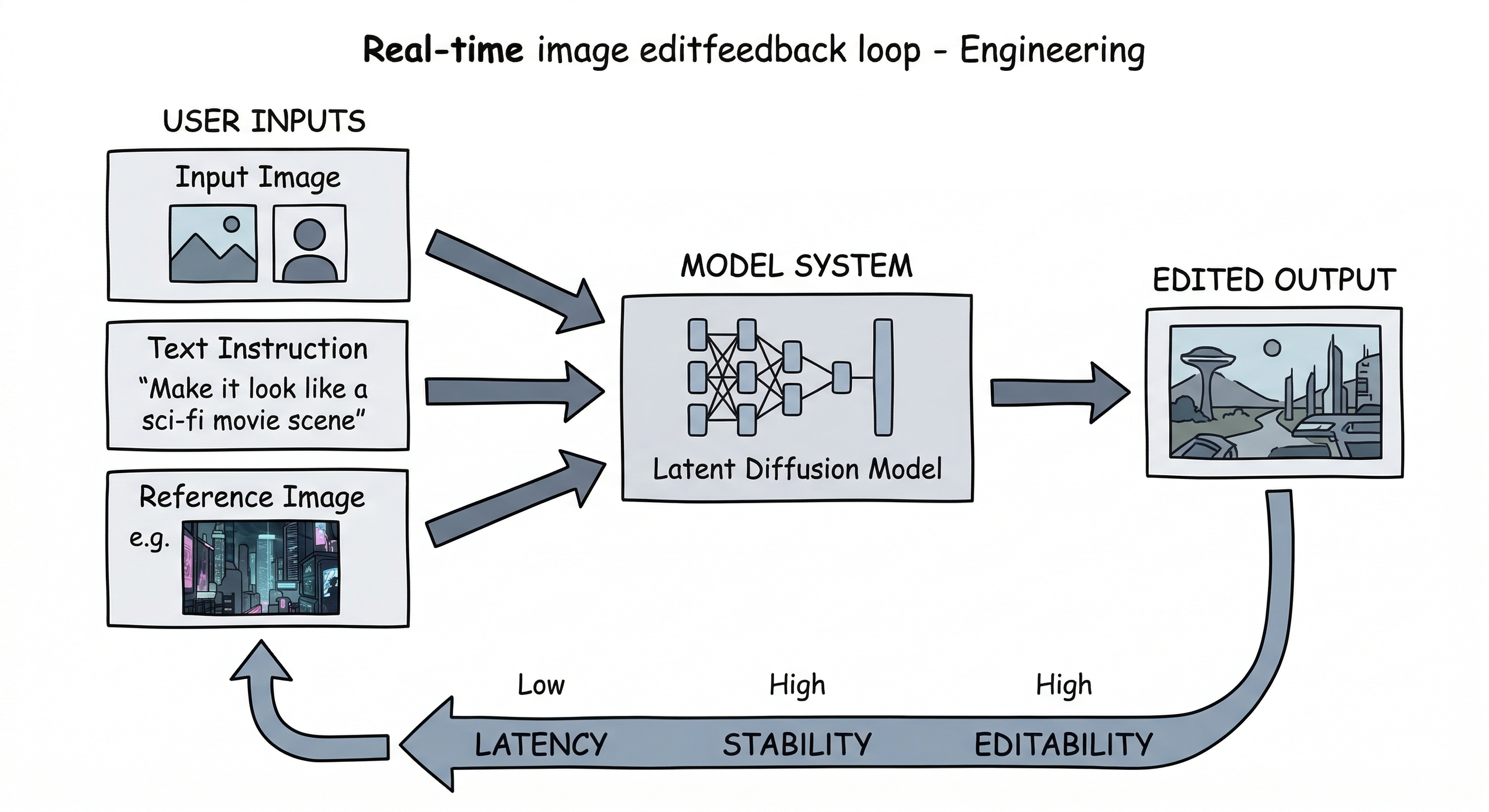 The real-time editing loop: an input image, a text instruction, and references flow into the latent diffusion model and produce an edited result. For the system to feel interactive, low latency, high stability, and strong editability all have to hold at once.
The real-time editing loop: an input image, a text instruction, and references flow into the latent diffusion model and produce an edited result. For the system to feel interactive, low latency, high stability, and strong editability all have to hold at once.
Preview Notice: This post describes a partially integrated system. Latency and FPS numbers reflect the current inference stack only; causal attention distillation and reward-guided DMDR are validated separately but not yet fully integrated.
Real-Time Editing as a Systems Problem
The target is low end-to-end latency under product constraints: the model must react quickly, outputs must remain stable across consecutive edits, and edit fidelity must hold. A 40 ms result that ignores the instruction is not fast; it is broken.
This framing filtered out many optimizations that improved isolated benchmarks but not the actual product.
Representative Runtime Breakdown
On a single H100, a representative optimized two-step configuration reached the following stage breakdown:
| Stage | Latency (ms) | Share |
|---|---|---|
| Prepare | 12.60 | 18.9% |
| Denoise | 36.10 | 54.3% |
| Decode | 17.82 | 26.8% |
| Total | 66.52 | 100% |
This corresponds to 15.03 FPS. It is not the fastest configuration, but it is representative: denoising still dominates, while preparation and decoding are large enough to matter. That breakdown shaped the engineering decisions that follow.
With the more aggressive FA3 + TAEF2 + compile stack, the best measured runtime improved further to 53.55 ms (18.67 FPS)—detailed later in the VAE optimization section.
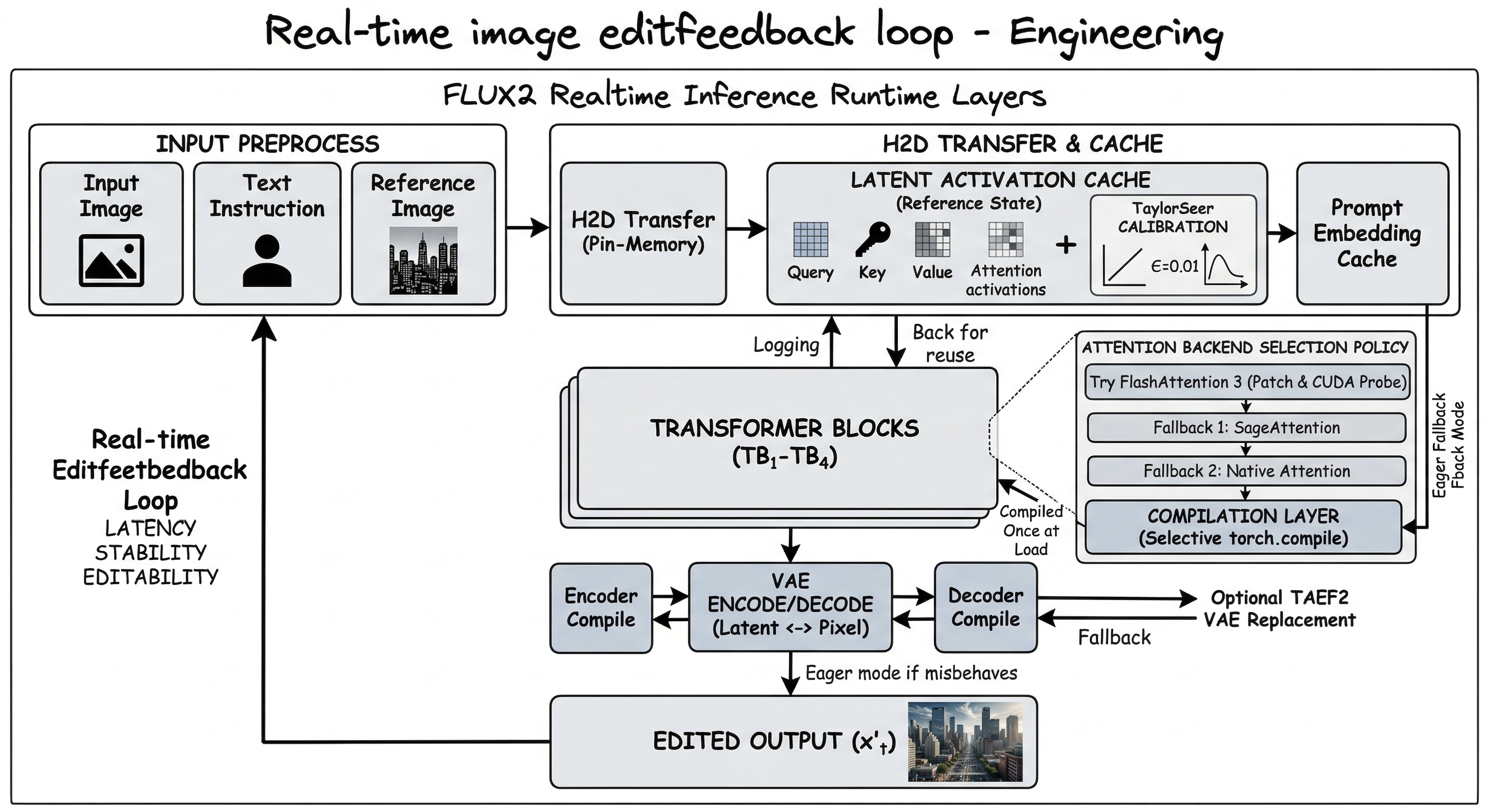
Inference Acceleration: Cache for Two-Step Editing
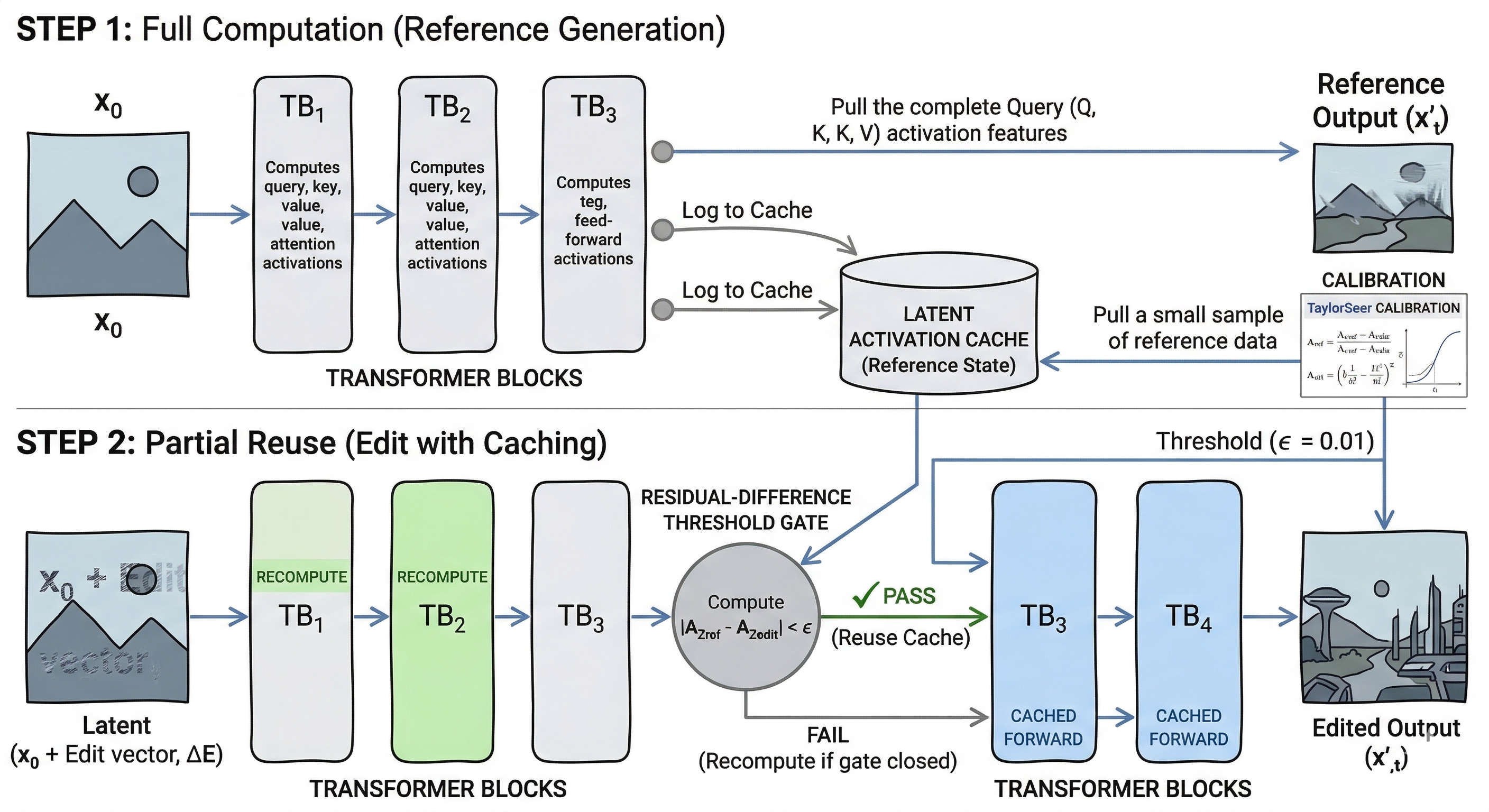
The biggest gain came from caching, specifically DBCache from Cache-DiT. With only two denoising steps, every unnecessary block execution becomes disproportionately expensive.
Key implementation choices:
Step-aligned masking: The cache aligns with the two-step regime using mask
"10"—first step computed fully, second step allowed to reuse cached activations.Dynamic thresholding: A residual-difference threshold gates cache reuse. Lower thresholds are safer; higher thresholds are faster.
TaylorSeer calibration: Acts as a local correction mechanism for the skipped-compute regime.
Per-request refresh:
refresh_context(...)is mandatory. Stale cache state in a real-time service leads to incorrect reuse decisions.
Cache reduces work across the full denoising path rather than speeding up a few isolated operators. Once per-request state and latent packing were stabilized, it also reduced variance in the preparation stage.
Inference Acceleration: Faster Kernels and Runtime
With cache in place, the next target was operator speed. This was not just optimization; it was a serving-path refactor: dismantling the default offline Diffusers pipeline and reorganizing it around a path built for real-time serving.
Attention Backend Selection
This was not just about choosing FlashAttention 3. It was about making backend selection robust enough for production: automatic FA3 → Sage → Native fallback, compatibility patching for Diffusers attention dispatch, runtime probing to verify that each interface actually works, and graceful degradation when it does not. The fastest backend is only useful if it does not crash the service.
Selective Compilation
torch.compile is applied selectively for stability: the transformer at load time, and the VAE encoder and decoder as separate branches. If a compiled branch fails at runtime, the system falls back to eager mode for that branch only. This is not “compile everything and hope”; it is selective compilation with per-branch fallback, prioritizing serving stability over benchmark speed.
VAE Optimization
At very small step counts, VAE encoding and decoding account for a significant share of total latency. TAEF2 provides a faster VAE replacement.
Results
Attention backend comparison:
| Backend | Total (ms) | Prepare (ms) | Denoise (ms) | Decode (ms) | FPS |
|---|---|---|---|---|---|
| SageAttention | 79.03 | 21.95 | 36.90 | 20.18 | 12.65 |
| FlashAttention 3 | 64.49 | 13.30 | 33.70 | 17.49 | 15.51 |
VAE compile impact:
| Encoder compile | Total (ms) | Prepare (ms) | Decode (ms) | Denoise (ms) | FPS |
|---|---|---|---|---|---|
| Off | 74.90 | 15.16 | 18.67 | 41.08 | 13.35 |
| On | 66.52 | 12.60 | 17.82 | 36.10 | 15.03 |
TAEF2 VAE path (with FA3):
| VAE path | Total (ms) | Prepare (ms) | Denoise (ms) | Decode (ms) | FPS |
|---|---|---|---|---|---|
| Baseline VAE | 70.40 | 16.82 | 34.69 | 18.89 | 14.21 |
| TAEF2 eager | 56.79 | 12.54 | 33.63 | 10.63 | 17.61 |
| TAEF2 + compile | 53.55 | 11.94 | 33.69 | 7.91 | 18.67 |
The denoising cost barely changed across the TAEF2 variants, so the attribution is clean: the gain comes from shrinking the VAE path, not from side effects in the diffusion loop.
Serving-Path Refinement
The serving-path refactor went beyond the major components. In addition to cache, kernels, and VAE work, I rewrote much of the runtime glue around Diffusers to better fit a real-time serving path. None of these changes was dramatic on its own, but together they turned the pipeline into a real-time system rather than a repackaged offline diffusion pipeline:
| Optimization | Description |
|---|---|
| Prompt caching | Prompt embeddings and text IDs are cached and reused when the prompt stays the same, removing repeated text-encoding overhead during interactive editing. |
| Fast image preprocessing | Replaced generic preprocessing with a faster PIL → NumPy → Torch path, while keeping pinned memory and non-blocking H2D transfers to reduce input overhead. |
| Latent packing cleanup | Rewrote latent preparation, packing, and multi-image conditioning assembly to remove unnecessary tensor reshaping and reduce repeated allocations. |
| Timestep caching | Cached timestep lookup by latent sequence length, step count, and device, avoiding repeated schedule construction. |
| Image latent-ID caching | Cached latent IDs by shape and device, reducing repeated preparation in the conditioning path. |
| Multi-reference handling | Kept the main image on the compiled VAE encode path while forcing reference images through eager encode to avoid compile stalls caused by resolution mismatch. |
| Custom decode path | Split latent unpacking, normalization, unpatchifying, and VAE decode into a dedicated path for cleaner compilation, profiling, and recovery. |
| Serving behavior | Used a latest-frame overwrite strategy that prioritizes the newest useful frame instead of faithfully processing stale ones. In real-time editing, returning an outdated result is worse than skipping a frame. |
| Binary transport | Reduced avoidable transport overhead with binary endpoints (/api/predict_binary, /ws/predict) instead of base64, as a reminder that not all latency comes from the model itself. |
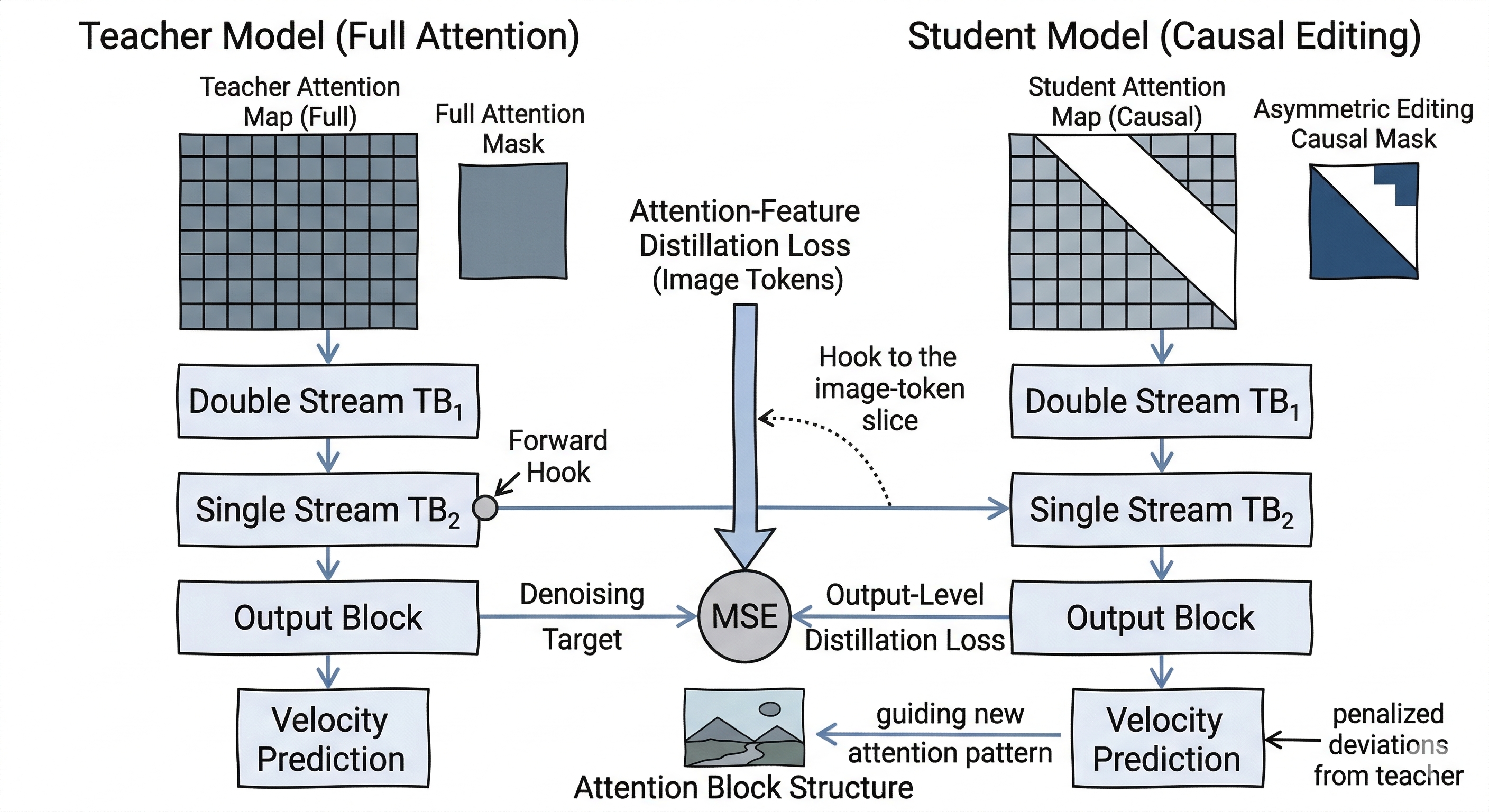
Training Acceleration: Attention Distillation for Causal Editing
The first training track changed the model’s attention geometry. The second changed the optimization target.
Inference optimization alone eventually hit a structural limit. FLUX2-4B-Klein was built for full in-context learning. That is powerful, but it is not ideal for real-time editing, where instruction and reference information need to flow efficiently into editable image tokens.
The solution: distill the full-attention teacher into a causal-editing student with an asymmetric editing mask.
What Did Not Work
- Output-level distillation alone: The student matched denoising targets but failed to inherit correct editing behavior under the new mask.
- Naive attention distillation: Matching generic internal features is insufficient when information flow architecture changes.
What Worked
Where supervision is applied matters. The final setup uses two signals:
- Output distillation: The student predicts the denoising target and is penalized for deviating from the teacher velocity.
- Attention-feature distillation on image tokens: Forward hooks collect attention outputs from double-stream and single-stream transformer blocks, and the loss is applied only to the image-token slices where edit behavior is expressed.
Matching only the final outputs was too weak. Matching the wrong internal features spread the supervision too broadly. Matching the right attention outputs transferred the causal editing behavior we wanted.
This creates a clean bridge between training and deployment: the more the model internalizes efficient causal editing paths, the less the serving system has to fight the architecture.
The evidence here is behavioral rather than scalar: one-step vs two-step ablations, copy-paste and structure-transfer tests, baseline comparisons, and controllability after the mask change.
Training Acceleration: DMDR with Pairwise Reward
Once the model is in a causal-editing regime, the next question is how to push it into a very small step budget without training against a misaligned objective.
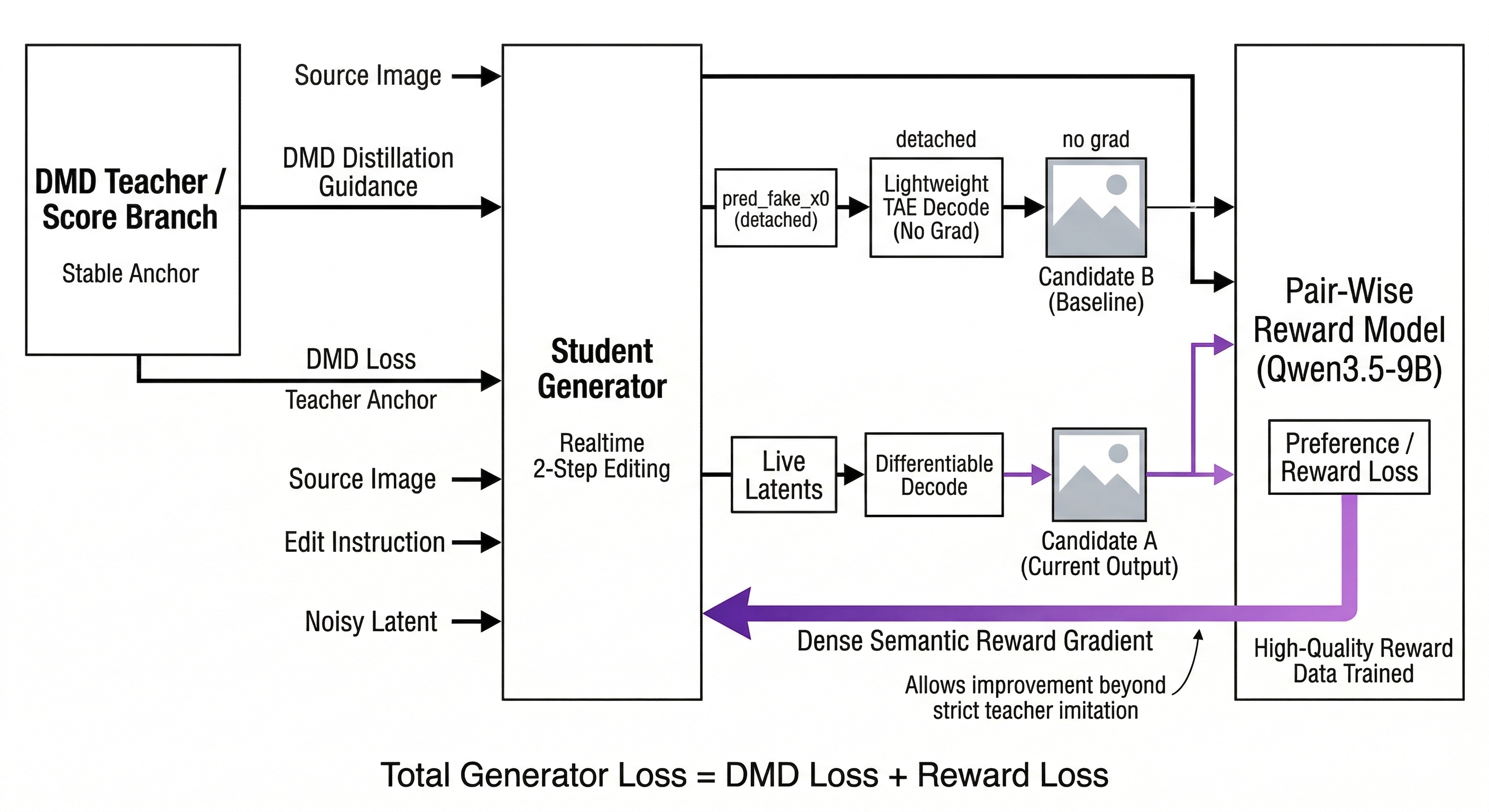
DMDR Structure
DMDR keeps the standard DMD structure, but makes the generator update better suited to few-step editing. The critical difference is how the reward is integrated.
Traditional preference pipelines use reward models as outer-loop evaluators that emit sparse terminal scalars. Editing needs denser signals.
Pairwise EditReward
A pairwise EditReward model (Qwen3.5-9B backbone) is trained on high-quality editing preference data. Given a source image, a generator output, a baseline candidate, and an edit instruction, it answers a simple question: is candidate A better than candidate B for this edit?
The pairwise formulation is sharper than absolute scoring for editing. More importantly, the reward is wired directly into the loss as a differentiable term:
The gradient flows through the generated image and back into the generator. The reward model does not merely score samples; it acts as a semantic teacher through the image manifold.
Why This Matters
Pure distillation caps the student at teacher quality. But the teacher may not be optimal for a few-step, deployment-driven objective. The reward model introduces a second supervision axis: the teacher provides stability, while the reward model pushes toward better edits under the target criterion.
The qualitative comparisons below show the source image, stronger and weaker FLUX2 variants, plain DMDR, reward-guided DMDR, and Nanobanana results under identical prompts and 2-step settings.

 All results use the same prompt, same 2-step budget, and same evaluation setup.
All results use the same prompt, same 2-step budget, and same evaluation setup.
DMDR turns preference modeling from a sparse outer-loop evaluator into a dense inner-loop training signal, which is exactly what a few-step real-time editor needs.
Summary
Real-time editing requires optimizing the whole stack, not collecting isolated tricks.
Inference: Gains came from cache-aware two-step editing, stable backend selection, and eliminating unnecessary work. The best measured runtime reached 53.55 ms (18.67 FPS) on a single H100.
Model: Reshaping the architecture into a causal editor, then using reinforcement learning to align distillation with the outcomes that matter.
Integration: The systems and training work were different paths toward the same constraint—making real-time interaction the primary design target from day one.
Real-time editing did not emerge from a single breakthrough. It emerged from making the whole stack obey the same constraint.
Note: Speed numbers reflect the current inference stack only; final integrated performance with causal attention distillation is still in progress.